


C’est drôle comme ça se passe. Vous demandez des choix, puis vous vous sentez dépassé quand vous les obtenez. Vous pensez : « Wow, c’est trop de choix. Comment choisir ? »
Eh bien, c’est un peu comme ça dans Microsoft Fabric. Vous avez tous les outils à portée de main : flux de données, pipelines de données, notebooks et flux d’événements. Mais maintenant, la vraie question est de savoir quel outil utiliser et quand.
Le bon outil pour le bon travail
- Flux de données dans Power BI – Les flux de données sont disponibles dans Power BI depuis un certain temps. Ils constituent un outil puissant pour l’extraction, la transformation et le chargement (ETL) des données. Les développeurs utilisent une interface graphique qui permet aux utilisateurs de transformer les données à l’aide d’une approche par glisser-déposer. Cet environnement à faible code/sans code est particulièrement attrayant pour les développeurs citoyens et ceux qui n’ont peut-être pas une expertise approfondie en matière de codage. Bien que la simplicité de l’interface soit un grand avantage pour permettre un développement rapide et un accès rapide aux données, cela signifie que les flux de données manquent de certaines des fonctionnalités avancées que l’on trouve dans des outils ETL plus robustes.
- Pipeline de données – Considérez un pipeline de données comme la structure globale qui relie diverses tâches. Il sert de couche de contrôle (semblable au volet de contrôle dans SQL Server Integration Services) et fournit la « plomberie » à travers laquelle les données se déplacent. Alors que le contenu qui traverse le pipeline est la donnée réelle, le pipeline lui-même gère comment, quand et où les tâches de traitement des données se produisent. Les pipelines de données sont très polyvalents et efficaces pour gérer des modèles, exécuter des notebooks et orchestrer des flux de travail de données. Une fonctionnalité exceptionnelle est la tâche Copier les données, qui est souvent utilisée pour l’ingestion de données. La fonctionnalité Copier les données rationalise le transfert de données entre différentes sources et destinations tout en garantissant la cohérence et l’exactitude des données.
- Notebooks – Les notebooks offrent un environnement très flexible et interactif pour l’écriture et l’exécution de code. Ils sont principalement utilisés pour le codage en Python mais prennent également en charge les commandes Spark SQL, permettant un mélange de paradigmes de programmation pour s’adapter à différents cas d’utilisation. Le format notebook est particulièrement avantageux pour les scientifiques des données et les développeurs qui ont besoin d’une flexibilité maximale lorsqu’ils travaillent dans l’écosystème Fabric. Les notebooks sont idéaux pour écrire des scripts personnalisés pour une manipulation de données complexe, l’apprentissage automatique ou l’analyse avancée. Ils offrent beaucoup plus de contrôle et de précision que les outils à faible code.
- Flux d’événements – Les flux d’événements sont spécialement conçus pour gérer le traitement des données en temps réel, en se concentrant principalement sur les opérations « d’insertion uniquement ». Ils sont idéaux pour travailler avec des données transactionnelles qui nécessitent une transformation minimale. Les flux d’événements excellent dans les scénarios où l’ingestion immédiate et continue de données est essentielle, comme la surveillance des capteurs IoT, la capture des interactions des utilisateurs en direct ou le traitement des transactions financières. Leur nature rationalisée garantit un traitement des données à faible latence, ce qui est essentiel pour les applications qui reposent sur des informations de dernière minute.
- Modèles sémantiques – C’est l’étape finale, où tout se rassemble et où les utilisateurs interagissent avec les données. Les agrégats et les calculs sont créés à l’aide de DAX. Bien que des transformations supplémentaires puissent être effectuées dans les modèles sémantiques, nous les gardons au minimum, en n’ajoutant que des mesures et des calculs qui prennent en charge la fonctionnalité de glisser-déposer de Power BI.
- Fichiers Wheel – Ce n’est pas une norme dans Fabric. C’est une fonctionnalité avancée dérivée des pratiques de développement Python. En fait, ce n’est pas du tout un outil Fabric, mais plutôt une capacité prise en charge. Les fichiers Wheel regroupent du code répétable dans un package que les développeurs peuvent appeler depuis les notebooks. En appliquant les meilleures pratiques orientées objet, nous réduisons la quantité de code nécessaire dans les notebooks, augmentons la réutilisabilité et réduisons les coûts de maintenance.
Quels outils nous choisissons
Le travail : ingestion de données depuis la source
- Les pipelines de données sont le choix évident ici. Avec la tâche Copier les données prenant en charge des tonnes de connecteurs, vous pouvez ingérer des données en utilisant des chargements complets ou incrémentiels.
- Avec notre cadre Fabric Manager, nous pouvons utiliser des entrées dynamiques pour parcourir plusieurs tables à l’aide d’un petit ensemble de code piloté par des paramètres.
- Les filigranes pour le chargement incrémentiel des données sont stockés dans une table et utilisés pour minimiser le débit de données redondant.
- Depuis mars 2025, la nouvelle tâche Copier la tâche simplifie encore plus cela. Chez Ateko, nous venons de l’ajouter à notre feuille de route des fonctionnalités. Actuellement en préversion, elle sera dotée de capacités de chargement incrémentiel prêtes à l’emploi.
Le travail : passer de la source à l’argent
- Nous utilisons des notebooks pour appeler notre fichier wheel. Cette approche offre la flexibilité totale du code personnalisé tout en gardant nos notebooks simples, lisibles et maintenables.
- Le notebook est ensuite intégré dans un pipeline qui prend les paramètres et enregistre tous les résultats
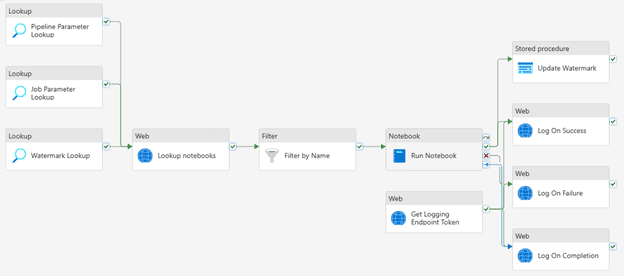
Le travail : passer de l’argent à l’or
- En utilisant la même approche que de la source à l’argent, nous utilisons un notebook qui appelle notre fichier wheel pour implémenter les tables de dimension et de faits.
- Le notebook est ensuite exécuté par les mêmes pipelines de données que ci-dessus.
- Cela se connecte à un notebook de configuration où la logique de dimension ou de fait est écrite en Spark SQL

Le travail : actualisation sémantique
- Nous avons choisi l’approche d’importation de données pour notre modèle sémantique. Bien qu’il existe des cas d’utilisation pour Direct Lake et Direct Query, les meilleures performances et interactions des rapports proviennent toujours de l’importation de données. Cette approche, cependant, nécessite des actualisations de données.
- Celles-ci peuvent être planifiées indépendamment des autres outils, mais nous choisissons d’être cohérents et d’utiliser un pipeline de données avec l’activité d’actualisation du modèle sémantique pour le planifier avec le reste de nos flux de travail de déplacement de données.
Le travail : journalisation
- Nous journalisons dans l’Eventhouse tout au long de la solution.
- Dans les pipelines de données, cela se fait avec une tâche Web. Dans les notebooks, nous capturons des métriques telles que la durée et les erreurs à l’aide de Loguru. Ces journaux sont ensuite présentés dans un rapport Power BI afin que les opérations évaluent la santé du système.
Leçons apprises
- Un inconvénient est que chaque connexion doit être codée en dur dans le pipeline de données Fabric lors de l’utilisation de la tâche de copie. Dans Azure Data Factory, cela peut être un paramètre, ce qui signifie que nous pouvons réutiliser un pipeline pour toutes les sources du même type.
- Par exemple : je construis un pipeline SQL et je le réutilise pour toutes les bases de données SQL, mais dans Fabric, je dois créer un pipeline et une connexion pour chaque source distincte. Au fur et à mesure que je parcours mes environnements supplémentaires, chacun doit également avoir sa propre connexion. À grande échelle, cela signifie beaucoup de duplication de pipelines et beaucoup de connexions à gérer.
- L’accès SPN vient de s’étendre à nouveau, et nous sommes impatients de l’ajouter également.
Ce que nous allons explorer ensuite
Nous gardons toujours un œil sur les nouveautés de Fabric, et quelques fonctionnalités récentes ont attiré notre attention :
- Tâche pour l’ingestion complète de la base de données : Cette nouvelle tâche rationalise le processus d’ingestion d’une base de données entière dans la couche bronze en une seule opération. Elle promet des gains d’efficacité majeurs pour les chargements de données initiaux et pourrait réduire considérablement le temps de configuration.
- Bibliothèques de variables pour la gestion de l’environnement : Récemment publiées, les bibliothèques de variables offrent un moyen centralisé de gérer les configurations spécifiques à l’environnement. Nous sommes ravis de voir comment cette fonctionnalité peut simplifier les déploiements et réduire les erreurs lors du déplacement de solutions entre les environnements de développement, de test et de production.
Conclusion
Avec autant d’outils disponibles dans Microsoft Fabric, le succès dépend de savoir quand et comment utiliser chacun d’eux. Des flux de données à faible code aux puissants notebooks et aux flux d’événements en temps réel, chaque pièce joue un rôle dans la création de solutions de données évolutives et intelligentes.
Ateko fournit des services gérés qui permettent aux clients d’adopter les solutions Fabric de Microsoft en plus d’autres services natifs d’Azure.
Au fur et à mesure que de nouvelles fonctionnalités sont déployées et que les capacités s’étendent, nous continuerons d’explorer comment tirer le meilleur parti de Fabric. Il y a toujours plus à découvrir dans Fabric, alors gardez un œil sur le prochain volet de notre série Aventures dans Fabric.

